On Call
Misadventures in Pager Duty
First time doing pager duty, with what I still call my "new job", despite having worked on this project for over a year, while concurrently keeping the prior project alive-ish. But that's another article altogether.
I signed up online and set up the schedule to include myself and two other new-ish folks to the on call rotation, and totally forgot about it. Two weeks later, Slack notified me that I was on call. I turned on notifications in the support channel so I wouldn’t miss anything and with no small amount of dread, waited and worked.
The first notice came at 10:30pm. I was already in bed when my phone binged. I read the request. Someone in Japan wasn’t getting the test content that they wanted to preview before sending to actual customers (100? 1000? 10,000? More?). It sounded important. The Slackbot had been set up - thank goodness - to send links to the Splunk logs on this specific communication.
I was immediately grateful to past-me, who had thoughtfully requested access to Splunk weeks ago. I had been interviewing with a monitoring company, I knew I had pager duty coming up, plus it’s always good to see under the hood. I clicked on the links and dashboards loaded with details about the 4+ application services this communication had used to be set up. Content was there. Audience was there. Shoot, everything looked like it should work.
I responded in the support channel, “Everything looks good on this end”. The previously frustrated user pinged back, “I figured it out, thanks for looking”.
Breathing a sigh of relief, I turned out my light and hoped the rest of the week on call would go this well.
 Pager duty. Image credit
Pager duty. Image credit
Spoiler alert: the rest of the week did NOT go that well.
Sure, almost all questions and issues were handled either by on call personnel in other teams when the issue related to their work, or by the all mighty Slackbot. I was even helpful on a couple of occasions.
Then Monday happened.
My on-call ended on Wednesday morning, I was so close to getting through without a 4 alarm fire, when our Jenkins instance stopped building with a less-than-helpful error message.
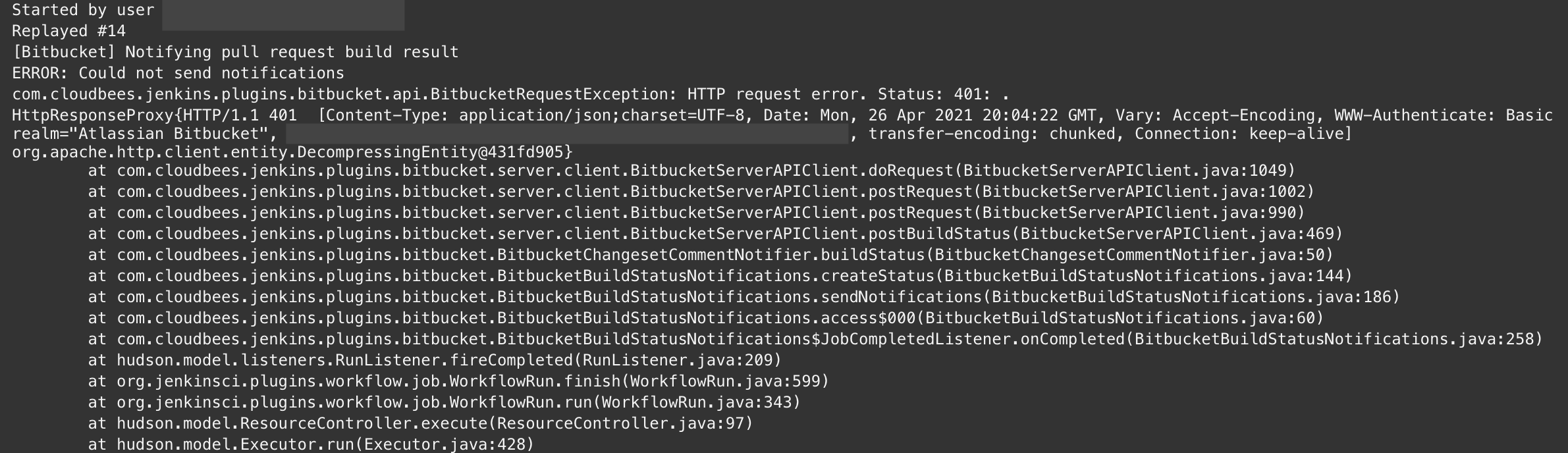 Less than helpful error message
Less than helpful error message
Teaming up with others, we tracked down the message as relating to the service user. Simple, right? Not quite. All continuous integration was halted. No CD happened. Which turned out to be in my on-call favor, since everyone on the team had a stake in making sure this was fixed.
I did turn off my computer on Monday evening at 8pm, with only one other person working with me on getting that service user account password updated and verified. I was up at 6am and online running tests while the electric tea kettle started to make my first cup of coffee water.
I took down nodes and restarted services. I ran test commits. 22 hours of work later in 2 days, and we had builds running again.
 Jenkins is Down
Jenkins is Down
Whew!
Do I know why? Ummmmm, no. There wasn’t a clear action with a clear resolution. Just one time when I did a push, the build started. It could have been any number of things that got that user account reset - even something I had done.
Just in time to migrate to another version control solution that didn’t require the service user account password.
 Sand in the Wind. Photo by Hassan OUAJBIR on Unsplash
Sand in the Wind. Photo by Hassan OUAJBIR on Unsplash